

目录:
概述编辑
--- 集群前端报错 ---编辑
该Redis节点无法正常使用,请及时检查该节点状态编辑
问题描述:
节点管理报错:该Redis节点无法正常使用,请及时检查该节点状态,如下图所示:

原因分析:
某个节点出现异常或已经宕掉,无法继续在 Redis 集群中提供服务。
解决方案:
1)登录 Redis 集群,输入cluster nodes检查 Redis 集群状态,如下所示:
./redis-cli -h ip -p 端口 -a 密码 #客户端远程连接某个节点,输入对应的ip、端口、密码

当检查到某个 Redis 节点是宕机(fail)状态,请及时检查该 Redis 节点进程,若进程还在,则 kill 掉进行重启,若进程不在,则直接启动该节点,启动后再次进行检查是否恢复。
2)如果想进一步确认 Redis 集群的可用性,可以连接某个主节点(master)测试是否能够写入 key
正常情况如下所示:

异常情况如下所示:

当检测到 Redis 集群是无法写入(down)的状态时,此种异常较为罕见,建议重启整个 Redis 集群。
该节点与XXX节点的JAR包不一致编辑
问题描述:
节点管理报错:该节点与XXX节点的jar包不一致,请及时更新jar包并重启该节点,如下图所示:

原因分析:
节点启动过程会与第一个加入集群的节点对比jar包是否一致,若检测到不一致情况,则前端进行异常展示并给出详细的异常信息。
解决方案:
参照异常提示, 检查各个节点下的 JAR 包并进行调整,调整完毕后重启节点,再观察是否还有报错。
集群节点XXX与基准节点存在不一致文件编辑
问题描述:
节点管理报错:集群节点XXX与基准节点存在不一致文件,且无法自动同步,请检查该节点状态,如下图所示:

原因分析:
该节点与文件同步基准节点进行文件同步时,出现同步错误或者请求超时,重复尝试 3 次仍然无法成功,则前端进行异常展示。
解决方案:
检查节点间通信、网络状态是否正常,若有异常则及时进行调整。
异常模块CLUSTER_MEMBER_MODULE编辑
问题描述:
集群节点页面标红,报错为:该节点存在异常的模块,暂无法正常提供服务,异常模块:CLUSTER_MEMBER_MODULE,如下图所示:
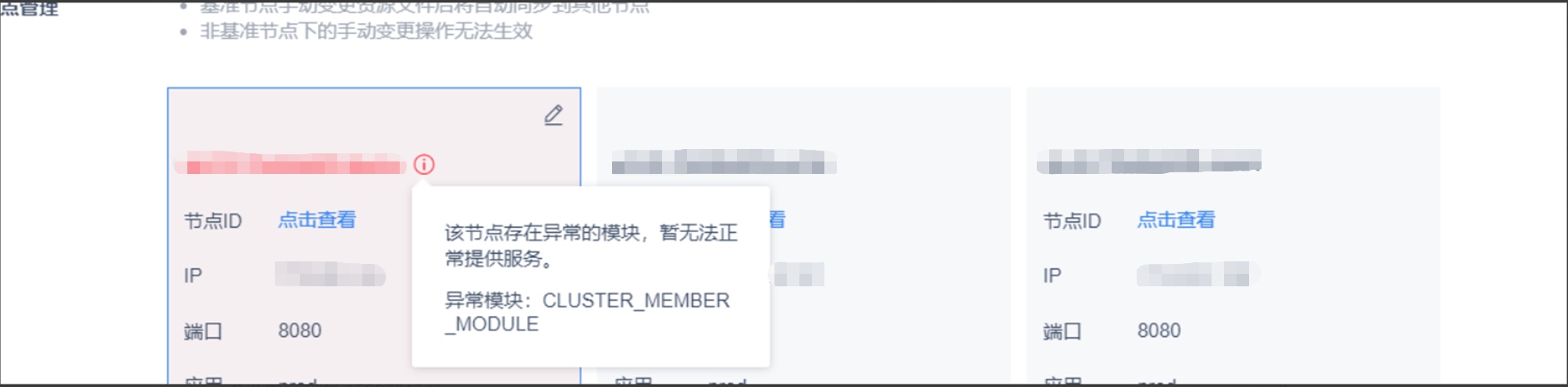
1)排查步骤一:检查节点数量
a)现象一:比如启动了 3 个节点, 但是页面上只能看到 2 个。
原因一:
集群通信异常
解决方案:
节点间 ip 是否能相互 ping 通。
排查7800,7830, 7840, 7850, 7870这 5 个集群通信端口是否有防火墙。
原因二:
获取到的网卡ip不对
解决方案:
集群配置页面,节点管理可以对节点信息进行编辑,修改 ip 地址为正确的 ip 地址,然后重启工程即可。详情请参见:配置开启集群 文档的 3.4 节内容。
b)现象二:单个节点只显示自己的节点,且节点飘红。
原因分析:
2021-07-13 和 2021-07-16 的 JAR 包,不支持同时启动, 得一个节点启动完成后再启动另一个。
解决方案:
升级到 2021-09-07 之后的JAR, 配置 hostname 对本地回环地址的映射后,启动正常,节点显示正常。
2)排查步骤二:检查页面节点数正常,但某个节点飘红
a)现象一:比如启动了 3 个节点, 页面上能看到 3 个,但还是某个节点标红,且显示异常模块:CLUSTER_MEMBER_MODULE
(集群刚启动,检测线程稍有滞后,等待一会刷新。等待 3 分钟后依然标红,此时说明确实有异常,此时要观察日志,往下排查。)
原因一:
redis里的节点数量> jgroups里的节点数量

后台日志中可见报错类似如下:
17:23:40 ClusterMemberHealthMonitorSchedule-14-worker-1 ERROR [standard] Cluster members may have errors. JGroupsNodes:[6bdaf2fa-2a6e-6b2e-b101-c96dc145f9c5, 72ca96f6a1bd9c72ffa52f02d83910ad005c03f751f6795af7df8aaf9ba43b20b49c330efe167feb], RedisNodes:[72ca96f6a1bd9c72ffa52f02d83910ad005c03f751f6795af7df8aaf9ba43b208b219ebaf96d8128, 6bdaf2fa-2a6e-6b2e-b101-c96dc145f9c5, 72ca96f6a1bd9c72ffa52f02d83910ad005c03f751f6795af7df8aaf9ba43b20b49c330efe167feb]
此时是有多个工程连接到了同一个 redis 环境, 且没有设置各自工程的 redis 前缀,导致 redis 里记录了其他集群的节点信息。
解决方案:
每个集群连不同的 redis, 不要共用。
给每个集群配单独的 redis 前缀
原因二:
jgroups里的节点数量 > redis里的节点数量,且报错 "[Cluster] node ***** cancel heartbeat",此时是因为集群节点的时间不同步, 导致检测线程异常。
解决方案:
b)现象二:两个节点各自显示另一个节点标红,且显示异常模块:“CLUSTER_MEMBER_MODULE”
原因分析:
集群通信异常。
解决方案:
节点间使用命令:ping -I eth0 ip
其中 eth0 要换成本机的网卡, ip要换成节点管理页面显示的另一个节点的ip, 如下图:

命令执行后查看是否有警告信息,如下图:
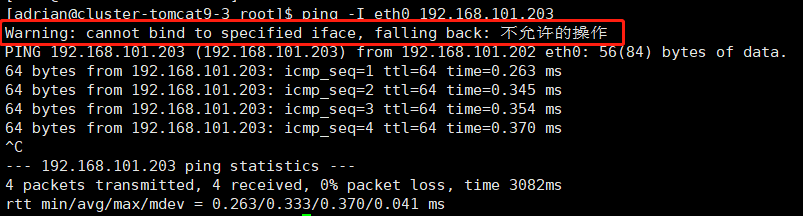
出现该警告,则表示当前用户没有这个命令的权限,需要更换 root 用户来启动工程,或者更换有权限的用户来启动工程,最好就是 root 用户。如果是 root 用户执行 ping 命令仍然提示权限不足,可能是 java 没有网卡权限,需要给 java 命令赋权:
sudo setcap cap_net_raw=ep /usr/java/jdk1.8.0_102/bin/java
java 的路径换成实际的,然后重启。
c)现象三:两个节点显示两个节点标红
双节点集群,每个节点单独访问正常,但是集群页面显示两个节点标红。后台报错:com.fr.third.jgroups.TimeoutException:timeout waiting for response from xxx
原因一:
由于内存压力大了,服务器半瘫痪,节点间通信超时导致的节点异常。
解决方案:
内存状态恢复后节点会自动恢复正常。
原因二:
Tomcat 下的 wabapps 文件夹放置了多个工程文件夹(多个 webroot ),导致工程重复启动。
解决方案:
将其他 webroot 移走。
原因三:
weblogic 和 WebSphere 容器部署时,重启工程需要将容器杀死再启动,不能通过容器的控制台来重启,否则会有线程残留,导致类似重复启动的情况,从而标红。
解决方案:
重启时杀死容器再启动,Tomcat 部署如果用 shutdown.sh 来停止也可能导致一样的问题。
Could not get a resource from the pool编辑
问题描述:
报表界面访问的时候,报错:Could not get a resource from the pool 如需访问请联系管理员,如下图所示:

原因分析:
Redis 宕机
网络异常
工程运行时修改了 Redis密码
解决方案:
如果是 Redis 宕机或网络异常,正常排查和解决即可
如果是 Redis 修改了密码需重启 Tomcat 工程,重启工程后进入平台页面重新配置 Redis 密码即可
--- 远程设计 ---编辑
服务器断开连接后远程设计没有提示断开编辑
问题描述:
设计器远程设计切换到某个节点之后,当服务器断开连接,远程设计没有提示断开连接。
原因分析:
1)现在弹窗触发 是基于Socket.IO 监听 disconnect 事件,但是这个事件断开后需要几秒到几十秒不等才会被响应 (这个时间没法把控 取决于断开的形式:
如果是服务器直接关闭的话,可以很快响应。
如果是 vpn 断开的话 响应较慢,响应后就会弹窗。
2)远程设计有自己的心跳机制,30s 进行一次连接校验。若连续超过3次校验失败,则判断为断开连接,这个目前也有断开的事件 90s+后被响应的情况,时间是可控的可配置的。
解决方案:
并不是远程设计没有断开,而是提示离开集群环境的响应弹窗出现速度比较慢,此问题在后续会进行优化。且后续产品中远程设计心跳断开也会提供提示。
启用 https 远程设计报错编辑
问题描述:
切换工作目录到远程环境,启用 https,服务器关掉之后,页面不会有提示。后台日志有报错;此时点击模板,会提示模板不存在。如下图所示:

原因分析:
现有的远程设计 websocket 不支持 https,目前仅支持 http,而远程连接断开提醒是基于 websocket 实现,所以不支持页面不会有提示。
解决方法:
使用 http 模式即可。
--- 集群启动后各节点只能看到自身节点信息 ---编辑
集群间无法通信编辑
问题描述:
集群间无法通信,各个节点只能看到自己的节点信息。
解决方案:
1)网络不允许 UDP 组播
如果网络不允许组波,而通信协议选择的是 UDP,需要改用 TCP。
2)防火墙未开放集群通信端口
对于 TCP,节点之间需要互相开放 7800, 7810, 7820, 7830, 7840, 7850, 7860, 7870 这八个端口;
对于 UDP,需要随机开放 45588~65536 端口中的一个,满足 UDP 访问。
IP 互相 ping 不通(网段和 IP 选择不当)
容器化部署web集群的时候使用的是bridge模式默认,导致不是同一台宿主机上面的节点不能 ping 通。
解决方案容器启动镜像的时候采用--net=host采用host模式
4)启动报错java.net.UnknownHostException: XXXX: XXXX: 未知的名称或服务
每个节点执行一下,以把 hostname 加到 /etc/hosts 的 127.0.0.1 记录中
sudo sed -i -e '/127.0.0.1/ s/\(localhost\)/'$(hostname)' \1/' /etc/hosts
5)ip 显示的不对,需要手动选择服务器实际的ip。
节点启动后互相 telnet 78xx 端口正常编辑
问题描述:
节点启动后互相 telnet 78xx 端口正常,各个节点只能看到自己的节点信息。
解决方案:
这种情况一般是两个节点的集群 id 不一致导致,检查两个节点WEB-INF/config/db.properties文件的 hibernate.connection.url 值是否一致(字面意思,要一模一样,不要使用 localhost),如果不一致表示属于不同集群,所以会出现节点看不到对方节点,对于使用 oracle 数据库的,还需要检查 hibernate.default_schema 是否一致。
节点 id 冲突编辑
问题描述:
节点 id 冲突,各个节点只能看到同一个节点的信息(2019.06以前版本)。
排查步骤:
1)到每个节点的集群配置/节点管理查看id是否冲突。
2)排查下面的原因:

docker部署
(同镜像同启动顺序时,docker 指定的 mac 地址是一样的),或者使用了桥接模式,没有第三方网络工具的情况下应使用 host 模式,让宿主机和容器共享 ip 和端口。
亚马逊服务器 EC2
(或者类似的虚拟服务器)上部署(和上面类似,没有独立的 mac 地址?)。
cluster.properties
手动在各机器 cluster.properties 指定了一样的节点 id。
Redis由单机模式变为集群模式无法登录编辑
集群部署时,状态服务器为 Redis,Redis 是单机非集群模式。
突然无法访问,访问报表登录http://ip:port/webroot/decision页面时,提示 Redis 的错误。无法登录,也无法修改状态服务器模式。
主要是状态服务器 Redis 的模式改变造成无法访问。Redis 模式由单机改为集群,状态服务器的模型由单机改为集群。
1)登录 MySQL 数据库,修改数据库表信息,SQL 语句如下:
update fine_conf_entity set value='false' where id='StateServerConfig.clusterMode';
update fine_conf_entity set value='false' where id='FineClusterConfig.params.cluster';
2)把各节点下的WEB-INF/config/cluster.config删除。
3)然后停止服务,重启各节点即可。